
Managing a single pool (continued)
(This post is part of a series on writing a process pool manager in Elixir.)
First, let’s point out the problem in our current pool design as we left after last post: our pool manager’s state gets out of whack when a checked out worker dies. Here’s how to witness that with your own eyes (after running iex -S mix from your project’s root folder, of course):
iex(1)> PoolToy.PoolMan.checkout()
#PID<0.137.0>
iex(2)> :observer.start()
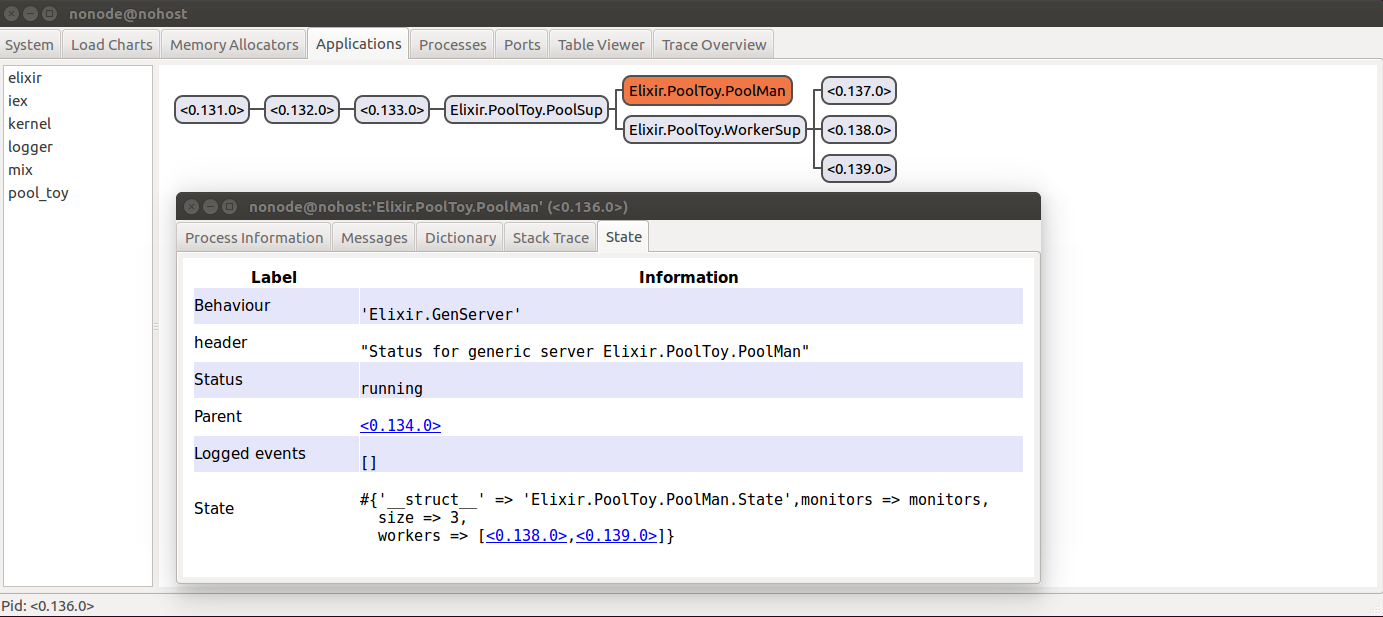
:okI’ve checked out a process with pid 0.137.0 (note that your value could of course be different) and started the Observer. In there, if I look at the pool manager’s state (quick reminder: in the “Applications” tab, click on pool_toy in the list on the left, then double-click on PoolMan, then go to the “State” tab in the new window), I can see that I now have only 2 available workers, which is correct:
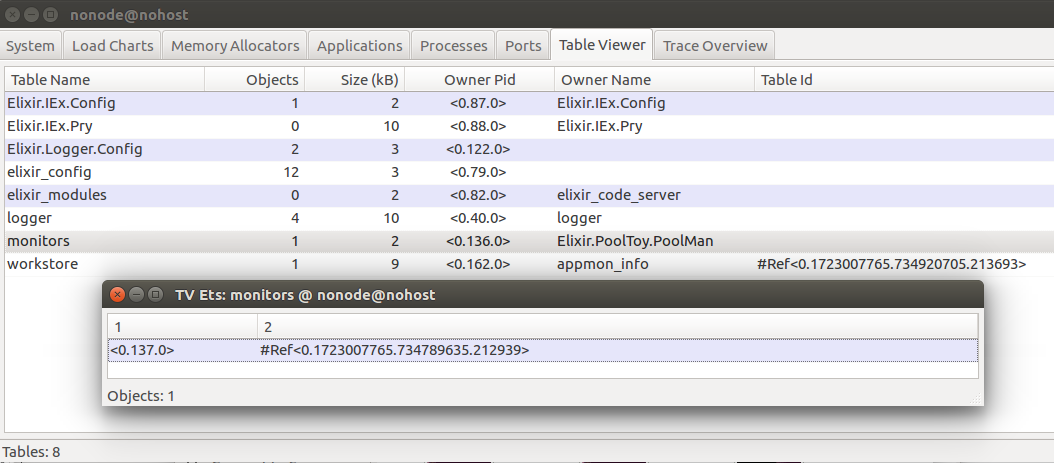
Additionally, if I go to the “Table Viewer” tab in the Observer and double click on the “monitors” table, I can see that we have an entry for a monitor on the process with pid 0.137.0:
Back in the “Applications” tab (where you might have to select pool_toy on the left again), let’s kill the checked out process by right-clicking on it and selecting the last entry in the menu: “kill process”. Click ok on the popup asking for the exit reason (thereby using the default :kill) and you’ll see our application quickly replaces the downed worker in the pool with a fresh new instance (it has a different pid) ready to accept a workload.
For completeness, let’s quickly point out that what we’ve just accomplished in the Observer (killing a specific process) can of course be achieved in code:
iex(1)> w = PoolToy.PoolMan.checkout()
#PID<0.137.0>
iex(2)> Process.exit(w, :kill)
trueAnd if you consult the docs, you’ll see that the default :kill reason proposed by the Observer is special: it forces the process to die unconditionally (more on that below).
But let’s get back to our earlier train of thought, and turn our attention back to the Observer: if we look at the pool manager’s state and the monitors table, what do we see? Only 2 workers are considered as available by the pool manager, and we will see an entry for the dead worker in the monitors table.
If we return to the “Applications” tab and kill one of the available workers, it gets even worse. Look at the pool manager’s state now, and you can see that it’s still the same. That means that we’ve got pids in there that are dead (and therefore shouldn’t be given to clients when they request a worker), and alive workers that aren’t in the list of available workers. Oh my!
So why is this happening? As you’ve probably guessed, it’s because we’re not handling worker death properly (or some might say we’re not handling it at all): we’ve got a supervisor watching over the workers and restarting them as they die, but the pool manager is never made aware of this, so it can’t react and update its state.
How can we fix it? I know: we can have the worker supervisor monitor its children, and notify the pool manager when one of them dies, along with the pid of the new worker it started to replace the dead one! NO. No no no. No. Supervisors only supervise.
Supervisors only supervise
Supervisors are the cornerstone of OTP reliability, so they must be rock solid. In turn, this means that any code we can put elsewhere doesn’t belong in the supervisor: less code means fewer bugs, which equals more robust supervisors.
Ok, so we can’t have the supervisor monitoring the processes, but someone’s got to do it, right? Let’s have the brains of our operation do it: the pool manager. But let’s think this through a bit before heading straight back to mashing our keyboards.
Our pool manager already makes the dynamic worker supervisor start workers. This way the pool manager knows what the worker pids are. So it’ll be pretty easy to monitor (or link!) them there. This way, when a worker dies, the pool manager gets a message and can react to it (start a new worker, monitor/link the new worker, and clean up the state so its consistent). Sounds like a plan, let’s get back to coding!
Handling worker death
Our pool manager needs to know when workers die. Should we use monitors or links for this? To determine which is more appropriate, we once again need to think about how the pool manager and worker deaths should affect one another.
If process A monitors process B and B dies, process A will receive a :DOWN message as we saw in part 1.6. But if A dies, nothing special happens.
If process A links process B and B dies, process A will be killed. Reciprocally, if A dies, B will be killed.
In our case, we’d like a mix of the two: we want the pool manager to know when a worker dies (so it can start a new worker and add it to the pool), but if the pool manager dies all workers should be killed (because the best way to ensure the pool manager’s state is correct is to start fresh with all new workers that will all be available).
As this is a common use case, OTP provides the ability to trap exits which in Elixir is achieved via Process.flag/2. To learn more about this, let’s see the Erlang docs we’re referred to:
When trap_exit is set to true, exit signals arriving to a process are converted to {‘EXIT’, From, Reason} messages, which can be received as ordinary messages.
Why is this useful? Let’s contrast it to the usual case for linked processes (again from the Erlang docs):
The default behaviour when a process receives an exit signal with an exit reason other than normal, is to terminate and in turn emit exit signals with the same exit reason to its linked processes. An exit signal with reason normal is ignored.
When a process is trapping exits, it does not terminate when an exit signal is received. Instead, the signal is transformed into a message {‘EXIT’,FromPid,Reason}, which is put into the mailbox of the process, just like a regular message.
An exception to the above is if the exit reason is kill, that is if exit(Pid,kill) has been called. This unconditionally terminates the process, regardless of if it is trapping exit signals.
So normally, if process A is linked to process B, when process B crashes it will send an exit signal to process A. Process A, upon receiving the exit signal will terminate for the same reason B did.
However, if we make process A trap exits by calling Process.flag(:trap_exit, true) from within the process, all exit signals it is sent will instead be converted into :EXIT messages that will sit in the process’ mailbox until they are treated. The exception in the last quoted paragraph documents the exception: if the exit reason is :kill, a process cannot trap the exit signal and will be terminated unconditionally. In other words, you can still force a process that trap exits to terminate: just call Process.exit(pid, :kill).
Back to our use case: by having the pool manager link to workers and trap exits, we’ll achieve exactly what we want. If the pool manager goes down, it will take all workers down with it, but if a worker dies, the pool manager won’t be killed: it’ll instead receive a :DOWN message that it can process as it pleases (in our case to replace the dead worker in the pool).
Linking worker processes
Let’s start by refactoring worker starting to extract it to it’s own function (lib/pool_toy/pool_man.ex):
def handle_info(:start_workers, %State{size: size} = state) do
workers =
for _ <- 1..size do
new_worker(PoolToy.WorkerSup, Doubler)
end
{:noreply, %{state | workers: workers}}
endWe’ve simply shifted the worker creation to within a new_worker/2 function on line 4. Here’s that function definition (lib/pool_toy/pool_man.ex):
def handle_info(msg, state) do
# editd for brevity
end
defp new_worker(sup, spec) do
{:ok, pid} = PoolToy.WorkerSup.start_worker(sup, spec)
true = Process.link(pid)
pid
endMost of that code is the same, we’ve only added line 7 where we call Process.link/1 which will link the calling process to the one given. That handles the linking part, but we still need to handle the exit trapping part. That’s pretty easy (lib/pool_toy/pool_man.ex):
def init(size) do
Process.flag(:trap_exit, true)
send(self(), :start_workers)
monitors = :ets.new(:monitors, [:protected, :named_table])
{:ok, %State{size: size, monitors: monitors}}
endLine 2 is the only addition required to make the magic happen: when a worker dies, our pool manager will no longer die with it, since it’ll now receive a special message instead.
Let’s take a quick peek at the Observer again:
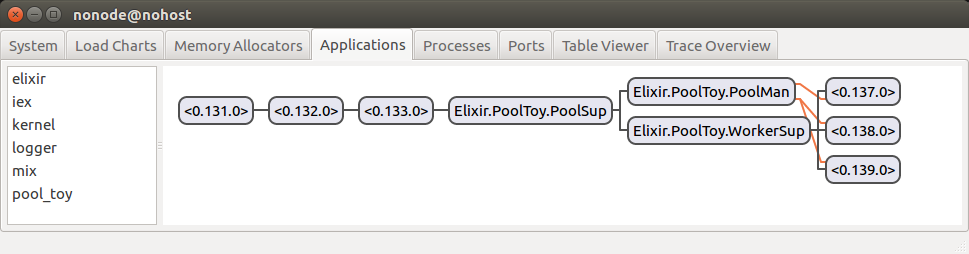
You can see that orange lines have appeared: they indicate link relationships. In the above image, we can see that PoolMan is linked to every worker process.
Handling a terminated worker
Let’s first write the code to handle a terminated worker. If a worker dies, we need to remove it from the list of available workers (if it even is in that list), and add a new worker to take its place. Of course, the new worker won’t have been checked out, so it’ll be added to the list of available workers (lib/pool_toy/pool_man.ex):
defp handle_idle_worker(%State{workers: workers} = state, idle_worker) when is_pid(idle_worker) do
# edited for brevity
end
defp handle_worker_exit(%State{workers: workers} = state, pid) do
w = workers |> Enum.reject(& &1 == pid)
%{state | workers: [new_worker(PoolToy.WorkerSup, Doubler) | w]}
endRight, so now let’s actually handle that mysterious :EXIT message that we’ll receive when a worker dies (because the pool manager is trapping exits) in lib/pool_toy/pool_man.ex:
def handle_info({:DOWN, ref, :process, _, _}, %State{workers: workers, monitors: monitors} = state) do
# edited for brevity
end
def handle_info({:EXIT, pid, _reason}, %State{workers: workers, monitors: monitors} = state) do
case :ets.lookup(monitors, pid) do
[{pid, ref}] ->
true = Process.demonitor(ref)
true = :ets.delete(monitors, pid)
{:noreply, state |> handle_worker_exit(pid)}
[] ->
if workers |> Enum.member?(pid) do
{:noreply, state |> handle_worker_exit(pid)}
else
{:noreply, state}
end
end
endThe :EXIT messages will contain the pid of the process that died (line 5). Since we’re only linking to worker processes, we know that this pid is going to be a worker. We can then check (on line 6) whether the worker was checked out, and act appropriately.
If the worker was checked out (line 7):
- stop monitoring the associated client, as we no longer care if it dies (line 8);
- remove the monitor reference from our ETS monitors table (line 9);
- handle the terminated worker and return the updated state (line 10).
If the worker wasn’t checked out (line 11):
- if the worker is in the list of available workers, we handle the terminated worker and return the updated state (lines 12-13);
- otherwise, we do nothing and return the state as is.
A quick refactor
We’ve got some “magic” module values strewn about our code: PoolToy.WorkerSup as the name for the worker supervisor process, and Doubler as the spec used for worker instances. Ideally, the @name module property we use to name the pool manager process should also get refactored, but as it is handled differently (being passed to GenServer.start_link/1 as opposed to used within the GenServer callback implementations), we’ll leave it aside for simplicity. Don’t worry, we’ll get to it when implementing multiple pools.
Hard coding process names everywhere works for now, but our end goal is to allow users to have multiple pools running at the same time. Our current approach won’t work for that: names must be unique. So let’s clean up our act by moving these values that are specific to a pool instance into the pool manager’s state. We’ll still hard code them for now, but at least that way they’ll be easier to change when the time comes.
Let’s start by adding these values to the state (lib/pool_toy/pool_man.ex):
defmodule State do
defstruct [
:size, :monitors,
worker_sup: PoolToy.WorkerSup, worker_spec: Doubler, workers: []
]
endAnd then we still need to refactor the rest of our code to work with this change (lib/pool_toy/pool_man.ex):
def handle_info(:start_workers, %State{worker_sup: sup, worker_spec: spec, size: size} = state) do
workers =
for _ <- 1..size do
new_worker(sup, spec)
end
{:noreply, %{state | workers: workers}}
end
# edited for brevity
defp handle_worker_exit(%State{workers: workers, worker_sup: sup, worker_spec: spec} = state, pid) do
w = workers |> Enum.reject(& &1 == pid)
%{state | workers: [new_worker(sup, spec) | w]}
end
Awesome! Start an IEx session with iex -S mix, start the Observer, and kill some workers. Does everything work as expected? Experiment a little, and try to figure out what could be going on… And move on to the next post!
Would you like to see more Elixir content like this? Sign up to my mailing list so I can gauge how much interest there is in this type of content.