
Managing a single pool (continued)
(This post is part of a series on writing a process pool manager in Elixir.)
After the last part, we’ve made some headway but still need some workers:
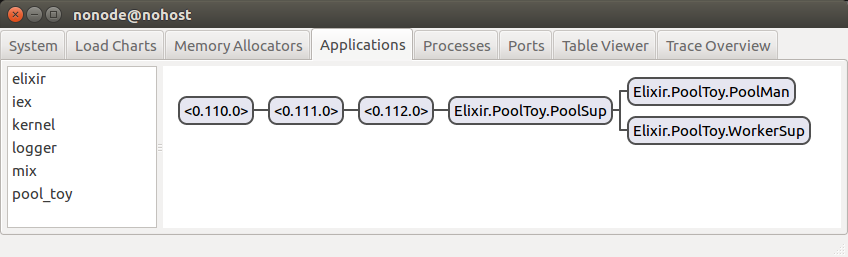 More useful state
More useful state
Let’s start by enhancing the state in the pool manager to be a struct: we’re going to have to remember a bunch of things to manage the pool, so a struct will be handy. In lib/pool_toy/pool_man.ex:
defmodule PoolToy.PoolMan do
use GenServer
defmodule State do
defstruct [:size]
end
@name __MODULE__
def start_link(size) when is_integer(size) and size > 0 do
# edited for brevity
end
def init(size) do
{:ok, %State{size: size}}
end
endStarting workers
Our pool manager must now get some worker processes started. Let’s begin with attempting to start a single worker dynamically, from within init/1. Look at the docs for DynamicSupervisor and see if you can figure out how to start a child.
Here we go (still in lib/pool_toy/pool_man.ex):
def init(size) do
DynamicSupervisor.start_child(PoolToy.WorkerSup, Doubler)
{:ok, %State{size: size}}
endstart_child/2 requires the dynamic supervisor location and a child spec. Since we’ve named our worker supervisor, we reuse the name to locate it here (but giving its pid as the argument would have worked also). Child specs can be provided the same way as for a normal supervisor: complete child spec map, tuple with arguments, or just a module name (if we don’t need any start arguments). We’ve gone with the latter.
Let’s try it out in IEx. When running iex -S mix we get:
Erlang/OTP 20 [erts-9.3] [64-bit] [smp:4:4] [ds:4:4:10] [async-threads:10] [hipe] [kernel-poll:false]
Compiling 6 files (.ex)
Generated pool_toy app
08:52:07.275 [info] Application pool_toy exited: PoolToy.Application.start(:normal, []) returned an error: shutdown: failed to start child: PoolToy.PoolSup
** (EXIT) shutdown: failed to start child: PoolToy.PoolMan
** (EXIT) exited in: GenServer.call(PoolToy.WorkerSup, {:start_child, {{Doubler, :start_link, [[]]}, :permanent, 5000, :worker, [Doubler]}}, :infinity)
** (EXIT) no process: the process is not alive or there's no process currently associated with the given name, possibly because its application isn't started
** (Mix) Could not start application pool_toy: PoolToy.Application.start(:normal, []) returned an error: shutdown: failed to start child: PoolToy.PoolSup
** (EXIT) shutdown: failed to start child: PoolToy.PoolMan
** (EXIT) exited in: GenServer.call(PoolToy.WorkerSup, {:start_child, {{Doubler, :start_link, [[]]}, :permanent, 5000, :worker, [Doubler]}}, :infinity)
** (EXIT) no process: the process is not alive or there's no process currently associated with the given name, possibly because its application isn't started
Oops. What’s going on? Well, let’s read through the error messages:
- The pool toy application couldn’t start, because:
- The pool supervisor couldn’t start, because:
- The pool manager couldn’t start, because:
- It tries calling a GenServer process called
PoolToy.WorkerSup, which fails because: - the process is not alive or there’s no process currently associated with the given name, possibly because its application isn’t started.
Wait a minute: the worker supervisor should be up and running with that name, since it was started by the pool supervisor! Let’s take a look at that code and see how the pool supervisor goes about its job of starting its children (lib/pool_toy/pool_sup.ex):
def init(args) do
pool_size = args |> Keyword.fetch!(:size)
children = [
{PoolToy.PoolMan, pool_size},
PoolToy.WorkerSup
]
Supervisor.init(children, strategy: :one_for_all)
endRight, so on line 9 the pool supervisor start its children. Which children? The ones defined on lines 4-7. And how are they started? The docs say
When the supervisor starts, it traverses all child specifications and then starts each child in the order they are defined.
So in our code, we start the pool manager and then move on to the worker supervisor. But since the pool manager expects the worker supervisor to already be up and running when the pool manager initializes itself (since it calls the worker sup), our code blows up.
Put another way, our software design has taken the position that the worker supervisor will ALWAYS be available if the pool manager is running. However, in our current implementation we’ve failed this guarantee quite spectacularly. (Take a look at what Fred Hébert has to say about supervisor start up and guarantees.)
The fix is easy enough: tell the pool supervisor to start the worker supervisor before the manager (lib/pool_toy/pool_sup.ex).
children = [
PoolToy.WorkerSup,
{PoolToy.PoolMan, pool_size}
]Try running PoolToy in IEx again, and not only does it work, you can actually see a baby worker in the Observer! Huzzah!
As a quick side note, the current example is quite simple and straightforward but initialization order needs to be properly thought through in your OTP projects. Once again, take a look at Fred’s excellent writing on the subject.
With our first worker process created, let’s finish the job and actually start enough workers to fill the requested pool size. Let’s get started with the naive approach (lib/pool_toy/pool_man.ex):
defmodule State do
defstruct [:size, workers: []]
end
def init(size) do
start_worker = fn _ ->
{:ok, pid} = DynamicSupervisor.start_child(PoolToy.WorkerSup, Doubler)
pid
end
workers = 1..size |> Enum.map(start_worker)
{:ok, %State{size: size, workers: workers}}
endPretty straightforward, right? Since we’re going to need to keep track of the worker pids (to know which ones are available), we add a :workers attribute (initialized to an empty list) to our state on line 2. On lines 6-9 we define a helper function that starts a worker and returns its pid. You’ll note that with the pattern match on line 7 we expect the worker creation to always succeed: if anything but an “ok tuple” is returned, we want to crash. Finally, on line 11 we start the requested number of workers, and add them to the state on line 13.
If you take this for a run in IEx and peek at the state for the PoolMan process, you’ll see we indeed have pids in the :workers state property, and that they match the ones visible in the application tab. Great!
Deferring initialization work
Actually, it’s not so great: GenServer initialization is synchronous, yet we’re doing a bunch of work in there. This could tie up the client process and contribute to making our project unresponsive: the init/1 callback should always return as soon as possible.
So what are we to do, given we need to start the worker processes when the pool manager is starting up? Well, we have the server process send a message to itself to start the workers. That way, init/1 will return right away, and will then process the next message in its mailbox which should be the one telling it to start the worker processes. Here we go (lib/pool_toy/pool_man.ex):
def init(size) do
send(self(), :start_workers)
{:ok, %State{size: size}}
end
def handle_info(:start_workers, %State{size: size} = state) do
start_worker = fn _ ->
{:ok, pid} = DynamicSupervisor.start_child(PoolToy.WorkerSup, Doubler)
pid
end
workers = 1..size |> Enum.map(start_worker)
{:noreply, %{state | workers: workers}}
end
def handle_info(msg, state) do
IO.puts("Received unexpected message: #{inspect(msg)}")
{:noreply, state}
endTake a good long look at this code, and try to digest it. Think about why each line/function is there.
First things first: in init/1, we have the process send a message to itself. Remember that init/1 is executed within the server process of a gen server, so send(self(), ...) will send the given message to the server process’ inbox.
Although we’re sending the message immediately, it’s important that nothing (e.g. starting new workers) will actually get done: the only thing happening is a message being sent. After sending the message, init/1 is free to do whatever it wants, before returning {:ok, state}. Only after init/1 has returned will the server process look in its mailbox and see the :start_workers message we sent (assuming no other message came in before).
Side note: if there’s a possibility in your project that a message could be sent to the gen server before it is fully initialized, you can have it respond with e.g. {:error, :not_ready} (in handle_call, etc.) when the state indicates that prerequisites are missing. It is then up to the client to handle this case when it presents itself.
Ok, onwards: we’ve sent a message to the server process so we need code to handle it. If a message is simply sent to a gen server process (as opposed to using something like GenServer.call/3), it will be treated as an “info” message. So on lines 6-15 we handle that info message, start the worker processes, and store their pids in the server state.
But why did we define another handle_info function on lines 17-20?
A short primer on process mailboxes
Each process in the BEAM has its mailbox where it receives messages sent to it, and from which it can read using receive/1. But as you may recall, receive/1 will pattern match on the message, and process the first message it finds that matches a pattern. What about the messages that don’t match any pattern? They stay in the mailbox.
Every time receive/1 is invoked, the mailbox is consulted, starting with the oldest message and moving chronologically. So if messages don’t match clauses in receive/1 they will just linger in the mailbox and be checked again and again for matching clauses. This is bad: not only does it slow your process down (it’s spending a lot of time needlessly checking messages that will never match), but you also run the risk of running out of memory for the process’ mailbox as the list of unprocessed messages grows until finally the process is killed (and all unread messages are lost).
To prevent this undesirable state of affairs, it is a good practice to have a “catch all” clause in handle_info/2 that will log the fact that an unprocessed message was received while also removing it from the process’ mailbox. In other words, it’s a good practice to have a catch all version of handle_info/2 to prevent unprocessed messages from piling up in the mailbox.
When we use GenServer, default catch all implementations of handle_info/2 (as well as handle_call/3 and handle_cast/2, which we’ll meet later) are created for us and added to the module. But as soon as we define a function with the same name (e.g. we write a handle_info/2 function as above) it will override the one created by the use statement. So when we write a handle_info/2 message-handling function in a gen server, we need to follow through and write a catch all version also.
Since these unexpected messages shouldn’t have been sent to this process, in production code we would most likely log them as errors using the Logger instead of just printing a message.
Improving the internal API
Right now we’re starting worker like so (lib/pool_toy/pool_man.ex):
{:ok, pid} = DynamicSupervisor.start_child(PoolToy.WorkerSup, Doubler)This isn’t great, because it means that our pool manager needs relatively intimate knowledge about the internals of the worker supervisor (namely, that it is a dynamic supervisor, and not a plain vanilla one). It also means that if we change how children get started (e.g. by setting a default config), we’d have to make that change everywhere that requests new workers to be started.
Let’s move the knowledge of how to start workers where it belongs: within the WorkerSup module (lib/pool_toy/worker_sup.ex):
defmodule PoolToy.WorkerSup do
use DynamicSupervisor
@name __MODULE__
def start_link(args) do
DynamicSupervisor.start_link(__MODULE__, args, name: @name)
end
defdelegate start_worker(sup, spec), to: DynamicSupervisor, as: :start_child
def init(_arg) do
DynamicSupervisor.init(strategy: :one_for_one)
end
endI’ve reproduced the whole module here, but the only change is on line 10: we define a start_worker/2 function, which in effect proxies the call to DynamicSupervisor.start_child/2. If you’re not familiar with the defdelegate macro, you can learn more about it here, but in essence the line we’ve added is equivalent to:
def start_worker(sup, spec) do
DynamicSupervisor.start_child(sup, spec)
endWith this addition in place, we can update our pool manager code to make use of it (lib/pool_toy/pool_man.ex):
def handle_info(:start_workers, %State{size: size} = state) do
workers =
for _ <- 1..size do
{:ok, pid} = PoolToy.WorkerSup.start_worker(PoolToy.WorkerSup, Doubler)
pid
end
{:noreply, %{state | workers: workers}}
endAt this stage in our journey, we’ve got a pool with worker processes. However, right now clients can’t check out worker processes to do work with them. Let’s get to that next!
Would you like to see more Elixir content like this? Sign up to my mailing list so I can gauge how much interest there is in this type of content.