
A new project
(This post is part of a series on writing a process pool manager in Elixir.)
Without further ado, let’s get started with PoolToy:
mix new pool_toyPools will contain worker processes that will actually be doing the work (as their name implies). In the real world, workers could be connections to databases, APIs, etc. for which we want to limit concurrency. In this example, we’ll pretend that doubling a number is expensive in terms of computing resources, so we want to avoid having too many computations happening at the same time.
Here’s our worker GenServer (lib/doubler.ex):
defmodule Doubler do
use GenServer
def start_link([] = args) do
GenServer.start_link(__MODULE__, args, [])
end
defdelegate stop(pid), to: GenServer
def compute(pid, n) when is_pid(pid) and is_integer(n) do
GenServer.call(pid, {:compute, n})
end
def init([]) do
{:ok, nil}
end
def handle_call({:compute, n}, _from, state) do
IO.puts("Doubling #{n}")
:timer.sleep(500)
{:reply, 2 * n, state}
end
endNothing fancy going on here: we’ve got a public API with start_link/1, stop/1, and compute/1 functions. As you can see from the return value in init/1, we’re not making use of state here, since our use case is so trivial. Finally, when handling a compute request on the server, we sleep for half a second to simulate expensive processing.
Also of note, the Doubler module is a the top level within the lib folder, and not within a pool_toy subfolder. This is because we really only have Doubler within PoolToy for convenience: if PoolToy became a fully-fledged library, the worker would be provided by the client code.
Managing a single pool
So what’s our pool going to look like? Roughly (ok, exactly…) like this:

No need to praise me for my elite design skills, this is straight from the Observer tool, which we’ll get to know better later on.
At the top level, we’ve got PoolSup which is responsible for supervising an entire pool: after all, once we’ve got several pools being managed, if one pool crashes the others should keep chugging along. Below that, we’ve got PoolMan and WorkerSup. PoolMan is the pool manager: it’s the process we communicate with to interact with the pool (such as borrowing a worker to do some work, then returning it).
WorkerSup supervises the actual worker processes: if one goes down, a new worker will be started in its place. The unnamed workers will be instances of Doubler in our case. After all, we didn’t write that module for nothing…
This nice little attroupement of processes is commonly referred to as a supervision tree: each black line essentially means “supervises” when read from left to right. You’ve probably heard of Erlang’s “let it crash” philosophy, and it goes hand in hand with the supervision tree: if something goes wrong within a process and we don’t know how to fix it or haven’t anticipated that failure, it’s best to simply kill the process and start a new one from a “known good” state.
After all, we do the same thing when our computers or phones start acting up, and no obvious actions seem to fix the issue: reboot it. Rebooting a device will let it start from a clean state, and fixes many problems. In fact, if you’ve ever had to provide some sort of IT support to friends or family, “Have you tried turning it off and on again?” is probably on of your trusty suggested remedies.

But why are we bothering with a worker supervisor and a pool manager? Couldn’t we combine them? While it’s definitely possible to do so technically, it’s a bad idea. In order to provide robust fault-tolerance, supervisors should essentially be near impossible to crash, which means they should have as little code as possible (since the probability of bugs will only increase with more code). Therefore, our design has a worker supervisor that only takes care of supervision (start/stopping processes, etc.), while the manager is the brains of the operation (tracking which workers are available, which process is currently using a checked out worker, etc.).
The pool supervisor
Let’s write our pool supervisor (lib/pool_toy/pool_sup.ex):
defmodule PoolToy.PoolSup do
use Supervisor
@name __MODULE__
def start_link() do
Supervisor.start_link(__MODULE__, [], name: @name)
end
def init([]) do
children = []
Supervisor.init(children, strategy: :one_for_all)
end
endOn line 2, we indicate this module will be a supervisor which will do a few things for us. Don’t worry about what it does for now, we’ll get back to it later.
We define a start_link/0 function on line 6 because, hey, it’s going to start the supervisor and link the calling process to it. Technically, the function could have been given any name, but start_link is conventional as it communicates clearly what the expected outcome is. You’ll note that we also give this supervisor process a name, to make it easier to locate later.
Naming processes
Since we expect there to be a single pool supervisor (at least for now), we can name the process to make it easier to find and work with.
Process names have to be unique, so we need to make sure we don’t accidentally provide a name that is already (or will be) in use. You know what else needs to be unique? Module names! This is one of the main reasons unique processes are named with their module name. As an added bonus, it makes it easy to know at a glance what the process is supposed to be doing (because we know what code it’s running).
But why have Supervisor.start_link(__MODULE__, [], name: @name) when Supervisor.start_link(__MODULE__, [], name: __MODULE__) would work just as well? Because the first argument is actually the current module’s name, while the name option could be anything (i.e. using the module name is just a matter of convention/convenience). By declaring a @name module attribute and using that as the option value, we’re free to have our module and process names change independently.
And now, back to our regularly scheduled programming
The supervisor behaviour requires an init/1 callback to be defined (see docs):
def init([]) do
children = []
Supervisor.init(children, strategy: :one_for_all)
endAt some point in the future, our supervisor will supervise some child processes (namely the “pool manager” and “worker supervisor” processes we introduced above). But for now, let’s keep our life simple and child-free ;-)
Finally, we call Supervisor.init/2 (docs) to properly set up the initialization information as the supervisor behaviour expects it. We provided :one_for_all as the supervision strategy. Supervision strategies dictate what a supervisor should do when a supervised process dies. In our case, if a child process dies, we want the supervisor to kill all other surviving supervised processes, before restarting them all.
But is that really necessary, or is it overkill? After all, there are other supervision strategies we could use (only restarting the dead process, or restarting the processes that were started after it), why kill all supervised processes if a single one dies? Let’s take another look at our process tree and think it through:
As mentioned above, PoolMan will take care of the pool management (checking out a worker, keeping track of which workers are busy, etc.), while WorkerSup will supervise the workers (replacing dead ones with fresh instances, creating a new worker if the pool manager asks for it, etc.).
What happens if PoolMan dies? Well, we’ll lose all information about which workers are checked out (and busy) and which ones can be used by clients needing work to be done. So if PoolMan dies, we want to kill WorkerSup also, because then once WorkerSup gets restarted all of its children will be available (and therefore PoolMan will know all workers are available for use).
You might be worried about the poor clients that checked workers to perform a task, and suddenly have that worker killed. The truth is, in the Erlang/Elixir world, you always have to think about processes dying, being unreachable, and so on: after all, the worker process could have died at any time and for whatever reason. In other words, the client process should have code to handle the worker dying and handle that case appropriately: after all, the worker process can die for any number of reasons (e.g. software bug, remote timeout) and not necessarily due to a supervisor killing it. And of course, the client process could very well decide that “appropriately handling the death of a worker process” means “just crash”. We are in the Erlang world, after all :D
Ok, so we’ve determined that if PoolMan dies, we should bring down WorkerSup along with it. What about the other way around? What happens if WorkerSup dies? We’ll have no more workers, and the accounting done within PoolMan will be useless: the list of busy processes (referenced by their pid) will no longer match any existing pid, since the new workers will have been given new pids. So we’ll have to kill PoolMan to ensure it starts back up with an empty state (i.e. no worker processes registered as checked out).
Since we’ve concluded that in the event of a child process dying we should kill the other one, the correct supervision strategy here in :one_for_one.
Poking around in Observer
Let’s start an IEx session and investigate what we’ve got so far. From within the pool_toy folder, run iex -S mix : in case you’ve forgotten, this will start an IEx session and run the mix script, so we’ll have our project available to use within IEx.
First, let’s start the pool supervisor with PoolToy.PoolSup.start_link(). Then, let’s start Erlang’s Observer with :observer.start() (note that autocompletion doesn’t work when calling Erlang modules, so you have to type the whole thing out): since Observer is an Erlang module, the syntax to call it is slightly different (because we use Erlang’s syntax). Here’s a quick (and very inadequate) primer on Erlang syntax: in Erlang, atoms are written in lower snake_case, while upper CamelCase tokens are variables (which cannot be rebound in Erlang). Whereas in Elixir module atom names are CamelCase while “normal” atoms are lower snake_case, in Erlang both are lower snake_case (i.e. a module name is an atom like any other).
To call an Erlang module’s function you join them with a colon. So in Erlang, foo:bar(MyVal) would execute the bar/1 function within the foo module with the MyVal variable as the argument. Finally, back in the Elixir world, we need to prepend the Erlang module’s name with a colon to make it an atom: the Observer module therefore gets referenced as :observer and :observer.start() will call the start/0 function within the Observer module. Whew!
Ok, so a new window should have popped up, containing the Erlang Observer :
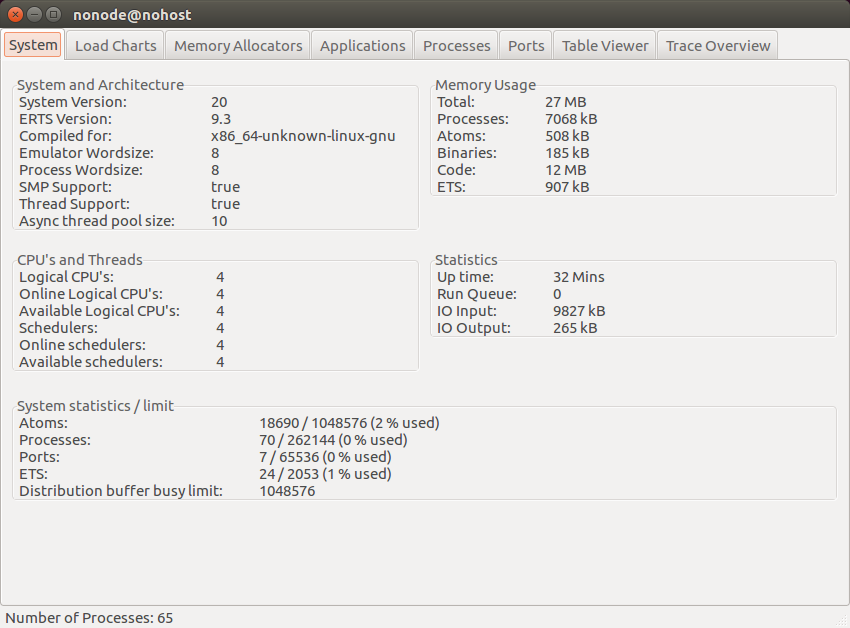
If nothing came up, search the web for the error message you get: it’s likely you’re missing a dependency (e.g. wxWidgets).
Click on the “Processes” tab, then on the “Name or Initial Func” header to sort the list of processes, then scroll down to Elixir.PoolToy.PoolSup which is the supervisor process we just created (don’t forget that Elixir prefixes all module names with Elixir). Let’s now open the information window for that particular process by double clicking on it (or right-clicking and selecting the “Process info for <pid>” option):
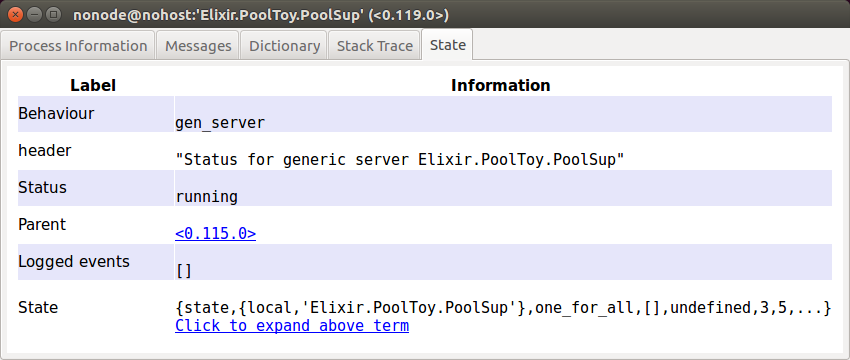
Notice that I’ve switched to the last tab, because that’s all we’ll be looking at for now. We can see a few things of interest here: our supervisor implements the GenServer behaviour, it’s running, and it’s parent process is <0.115.0> (this pid could very well be different in your case). If you click on the pid, a new window will open, where you’ll find out that the parent is indeed the IEx session (in the “Process Information” tab, the “Current Function” value is Elixir.IEx.Evaluator:loop/1).
We can also see our supervisor has some sort of internal state: click the provided link in the window to see what the state contains. You’ll see something like
{state,{local,'Elixir.PoolToy.PoolSup'},
one_for_all,{[],#{}},undefined,3,5,[],0,'Elixir.PoolToy.PoolSup',[]}This is the supervisor’s internal state (as Erlang terms), so we’re kind of peeking behind the curtains here, but we can see that the state contains the :one_for_all strategy, and the name of the module where we’ve defined the supervisor behaviour. Don’t worry about the other stuff: we’re looking at the internal details of something we didn’t write, so it’s not really our business to know what all that stuff is. It’ll be much more meaningful later when we observe processes where we defined the state ourselves (because then what the state contains will make sense to us!).
Take a break, and join me in the next post where we’ll implement the pool manager and have our supervisor start it.
Would you like to see more Elixir content like this? Sign up to my mailing list so I can gauge how much interest there is in this type of content.