Building a pool manager, part 1.9
This article is part of a series on writing a process pool manager in Elixir.
Managing a single pool (continued)
Figuring out the shenanigans
Let’s get on the same page (after last post) as to what is happening when we kill workers in our pool. After starting an IEx session with iex -S mix, starting the Observer with :observer.start(), and killing a worker, I’ve got the following state in my pool manager:
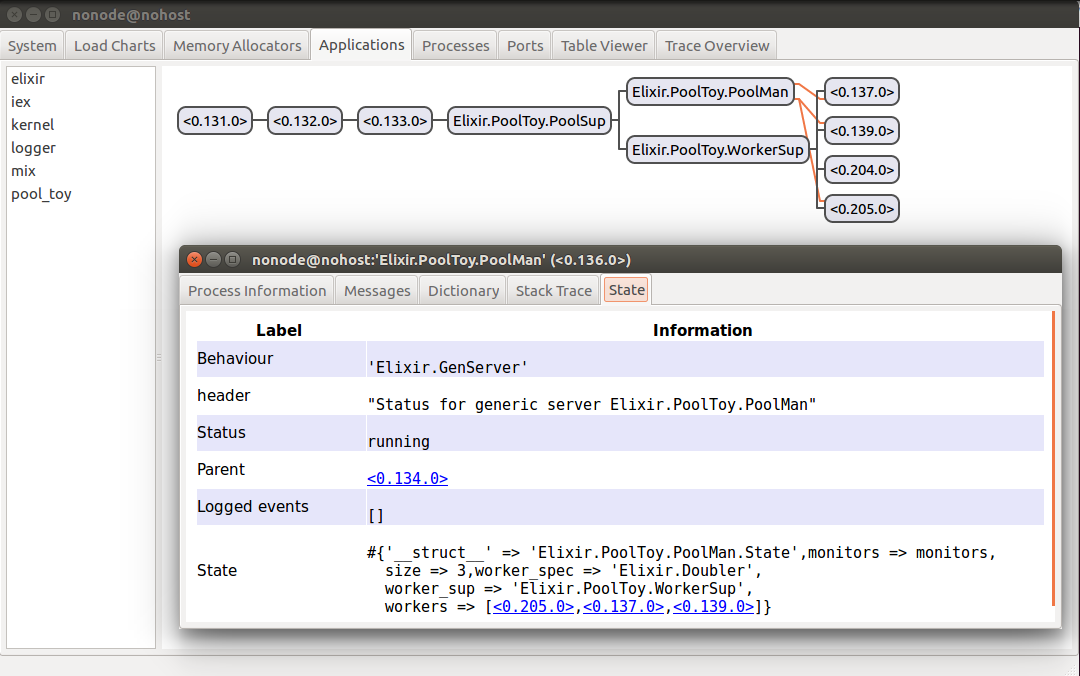
I started with 3 workers, but after killing one of them (0.138.0), I now have 4 workers (one too many). In addition, of the two new workers that appeared (0.204.0 and 0.205.0), only one of them was added to the pool manager’s list of available workers. You’ll notice that it was also the one to be linked. The other worker is just floating around, and will never be assignable to handle work.
Now, if I kill the process with pid 0.204.0, it gets replaced by a single new process. If on the other hand I kill 0.205.0, it will be replaced by two new processes. What gives?
Well, with the changes implemented in the last post, we’ve got the pool manager linked to all workers, and replacing them with new instances when they fail. But remember who else replaces worker processes as they die? That’s right: the worker supervisor. So when we killed a worker process that was spawned during initialization (and therefore linked to the pool manager), it triggered 2 responses: the worker supervisor started a new worker instances (because that’s just what it does), and the pool manager also started a new worker (which it then linked).
The new worker spawned by the worker supervisor isn’t linked by the pool manager (as you can see in the image above: no orange line), so we end up with different results when we kill these newly spawned workers:
- kill the worker created by the worker supervisor, and it simply gets replaced by a new worker: we don’t end up with any additional workers;
- kill the worker created by the pool manager, and we end up with an additional worker in our tree: one worker was created by the worker supervisor in response to a worker’s death, the other was created by the pool manager because it saw that a linked worker terminated.
This obviously isn’t the behavior we want in our application. What should we do? We need to tell the worker supervisor to not restart its children.
Supervisors start their children according to a child spec (that we met in back in part 1.2), which has a :restart optional value (see docs). This value dictates whether that particular child will get restarted when it terminates.
First, let’s check our current worker supervisor state by double-clicking on it within the Observer: in the “State” tab, you can see a list of children, each of which indicates permanent as the restart strategy.
Customizing the child spec
We’ve found the problem cause, let’s go for the solution. One possibility would be to ensure that our Doubler worker will always return a child spec with a :temporary restart strategy. We won’t go that route here, because down the road we want PoolToy users to be able to provide their own worker implementations to be used in the pool. So it’s safer if we ensure that workers have temporary restart strategies instead of relying on behavior implemented by others.
Here’s our current code starting workers (lib/pool_toy/pool_man.ex):
defp new_worker(sup, spec) do
{:ok, pid} = PoolToy.WorkerSup.start_worker(sup, spec)
true = Process.link(pid)
pid
end
We tell the dynamic worker supervisor to start a new instance of the spec argument. If you check the code, you’ll see that the value of that argument is always Doubler. How does that become a child specification? Well, Doubler invokes use GenServer: one of its effects is adding a child_spec/1 function to the module. Then when start_child/2 is given a second argument that isn’t a child spec (a child spec being simply a map with certain mandatory key/value pairs), it will convert it into a child spec.
If given a tuple with module and args like {Doubler, [foo: :bar]} it will call Doubler.child_spec([foo: :bar]) to get the child spec instance it needs (the args will then be forwarded to start_link/1). If given simply a module name such as Doubler it will call Doubler.child_spec([]) (so in effect Doubler is equivalent to {Doubler, []}).
In fact, you can try that in an IEx session with iex -S mix:
iex(1)> Doubler.child_spec([])
%{id: Doubler, start: {Doubler, :start_link, [[]]}}
So that explains how our dynamic worker supervisor ends up with the child spec it requires in the code above. And we know that we can provide a valid child spec directly to start_child/2, so maybe we could try:
defp new_worker(sup, spec) do
{:ok, pid} = PoolToy.WorkerSup.start_worker(sup,
%{id: spec, start: {spec, :start_link, [[]]}, restart: :temporary})
true = Process.link(pid)
pid
end
The problem there is that although that will technically work, it’ll be very brittle. What happens when Doubler changes how it defines its child specification (e.g. by adding default arguments provided to start_link/1)? Our code will disregard the change and will break, that’s what. Event worse, our code won’t work with other ways of specifying spec (e.g. a tuple, or the full map).
The better way would be to generate a child spec from the spec argument, and provide an override value for the :restart attribute. Fortunately, there’s a function for that: Supervisor.child_spec/2. It takes a child spec, tuple of module and args, or module as the first arg, and a keyword list of overrides as the second arg. So we can change our code to (lib/pool_toy/pool_man.ex):
defp new_worker(sup, spec) do
child_spec = Supervisor.child_spec(spec, restart: :temporary)
{:ok, pid} = PoolToy.WorkerSup.start_worker(sup, child_spec)
true = Process.link(pid)
pid
end
But hold on a minute: if the worker supervisor is no longer restarting terminated processes (since its children are now :temporary and the pool manager handles the restarting), is it even useful anymore? Shouldn’t we refactor and remove the supervisor? Nope, because one aspect of a supervisor is indeed that it handles restarting terminated children, but the other is that it provides a central location to terminate all of its children and prevent memory leaks. In other words, our worker supervisor will allow us to terminate all worker processes by simply terminating the worker supervisor itself. This will be particularly handy in the future, when we want to enable clients to stop pools.
And with that last change above, we’ve finally got a functional worker pool. Here it is in use:
iex(1)> w1 = PoolToy.PoolMan.checkout()
#PID<0.137.0>
iex(2)> w2 = PoolToy.PoolMan.checkout()
#PID<0.138.0>
iex(3)> w3 = PoolToy.PoolMan.checkout()
#PID<0.139.0>
iex(4)> w4 = PoolToy.PoolMan.checkout()
:full
iex(5)> PoolToy.PoolMan.checkin(w2)
:ok
iex(6)> w4 = PoolToy.PoolMan.checkout()
#PID<0.138.0>
iex(7)> Doubler.compute(w4, 3)
Doubling 3
6
iex(8)> 1..9 |> Enum.map(& Doubler.compute(w1, &1))
Doubling 1
Doubling 2
Doubling 3
Doubling 4
Doubling 5
Doubling 6
Doubling 7
Doubling 8
Doubling 9
[2, 4, 6, 8, 10, 12, 14, 16, 18]Since we’ve limited our pool size to 3 doublers, we know that at any one time only 3 doubling processes may happen simultaneously: that’s what we wanted by design to prevent becoming overloaded.
We’ve got a single functional pool, but there’s more for us to do (and learn!): clients should be able to start/stop as many pools as they want, with variable sizes and worker modules. We could also enhance our pool functionality to handle bursts of activity by allowing the pool to start a certain number of “extra” overflow workers that will shut down after some cool down time when demand returns to normal levels. We can also allow our clients to decide what to do if no worker is available: return a response immediately saying the pool is at capacity, or queue the client’s demand and execute when a worker becomes available.
Along the way, we’ll find that some choices made so far weren’t such a great design. But worry not! We’ll learn why and how our design will need to evolve to accommodate the new desired requirements.
On to the next post!
This article is part of a series on writing a process pool manager in Elixir.