Building a pool manager, part 1.5
This article is part of a series on writing a process pool manager in Elixir.
Managing a single pool (continued)
After last post, we’ve got a pretty fancy-looking pool:
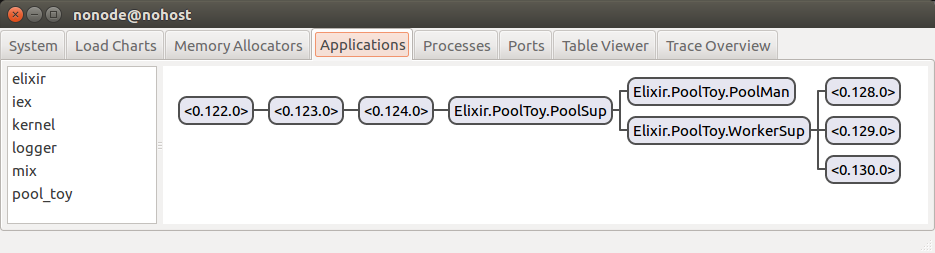
Unfortunately, we don’t have any sort of mechanism to make use of the worker processes. We need to let client processes check out a worker, do some work with it, and check the worker back in once the client is done with it.
Implementing worker checkin and checkout
In lib/pool_toy/pool_man.ex:
def checkout() do
GenServer.call(@name, :checkout)
end
def checkin(worker) do
GenServer.cast(@name, {:checkin, worker})
end
def init(size) do
# truncated for brevity
end
def handle_call(:checkout, _from, %State{workers: []} = state) do
{:reply, :full, state}
end
def handle_call(:checkout, _from, %State{workers: [worker | rest]} = state) do
{:reply, worker, %{state | workers: rest}}
end
def handle_cast({:checkin, worker}, %State{workers: workers} = state) do
{:noreply, %{state | workers: [worker | workers]}}
end
Pretty easy, right? Add checkout/0 and checkin/1 to the API (lines 1-7), and implement the matching server-side functions (lines13-23). When a client wants to check out a worker, we reply :full if none are available (line 14), and otherwise we provide the pid of the first available worker (line 18). When checking in a worker, we simply add that pid to the list of available worker pids (line 22). Note that since all workers are equal, there is no need to differentiate them and we can therefore always take/return pids from the head of the workers list (i.e. workers at the head of the list will be used more often, but we don’t care in this case).
But wait, how come this time around we didn’t implement catch-all clauses for handle_call/3 and handle_cast/2? After all, we had to add one for handle_info/2 back in part 1.4, why would these be different? Here’s what the
getting started guide
has to say about it:
Since any message, including the ones sent via
send/2, go tohandle_info/2, there is a chance unexpected messages will arrive to the server. Therefore, if we don’t define the catch-all clause, those messages could cause our [pool manager] to crash, because no clause would match. We don’t need to worry about such cases forhandle_call/3andhandle_cast/2though. Calls and casts are only done via theGenServerAPI, so an unknown message is quite likely a developer mistake.
In other words, this is the “let it crash” philosophy in action: we shouldn’t receive any unexpected messages in calls or casts. But if we do, it means something went wrong and we should simply crash.
We can now fire up IEx with iex -S mix and try out our worker pool:
iex(1)> w1 = PoolToy.PoolMan.checkout()
#PID<0.116.0>
iex(2)> w2 = PoolToy.PoolMan.checkout()
#PID<0.117.0>
iex(3)> w3 = PoolToy.PoolMan.checkout()
#PID<0.118.0>
iex(4)> w4 = PoolToy.PoolMan.checkout()
:full
iex(5)> PoolToy.PoolMan.checkin(w1)
:ok
iex(6)> w4 = PoolToy.PoolMan.checkout()
#PID<0.116.0>
iex(7)> Doubler.compute(w4, 21)
Doubling 21
42
Great success! We were able to check out workers until the pool told us it was :full, but then as soon as we checked in a worker (and the pool was therefore no longer full), we were once again able to check out a worker.
So we’re done with the basic pool implementation, right? No. When working in the OTP world, we need to constantly think about how processes failing will impact our software, and how it should react.
In this case for example, what happens if a client checks out a worker, but dies before it can check the worker back in? We’ve got a worker that isn’t doing any work (because the client died), but still isn’t available for other clients to check out because it was never returned to the pool.
But don’t take my word for it, let’s verify the problem in IEx (after either starting a new session, or checking all the above workers back into the pool):
iex(1)> client = spawn(fn -> PoolToy.PoolMan.checkout() end)
#PID<0.121.0>
iex(2)> Process.alive? client
false
iex(3)> :observer.start()
Within the Observer, if you go to the applications tab (selecting pool_toy on the left if it isn’t already displayed) and double-click PoolMan, then navigate to the “state” tab in the newly opened window, you can see that only 2 workers are available. In other words, even though the worker we checked out is no longer is use by the client (since that process died), the worker process will never be assigned any more work because it was never checked back into the pool.
How can we handle this problem? How about babysitting? Coming right up next!
This article is part of a series on writing a process pool manager in Elixir.